1. 一个爬虫的案例
案例:
- 使用爬虫,爬取豆瓣top电影信息
2.第一步
先在linux上下载python的插件
[root@elk91]# apt install -y python3-pip
然后下载几个库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
这里我们就可以写一下开头
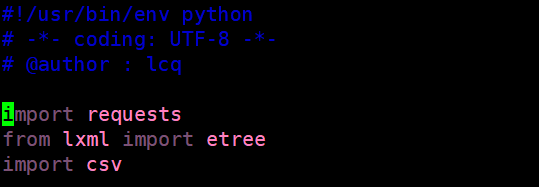
import 就是导入需要的python模块
3.第二步,我们就需要去爬取我们所需要的内容,全过程
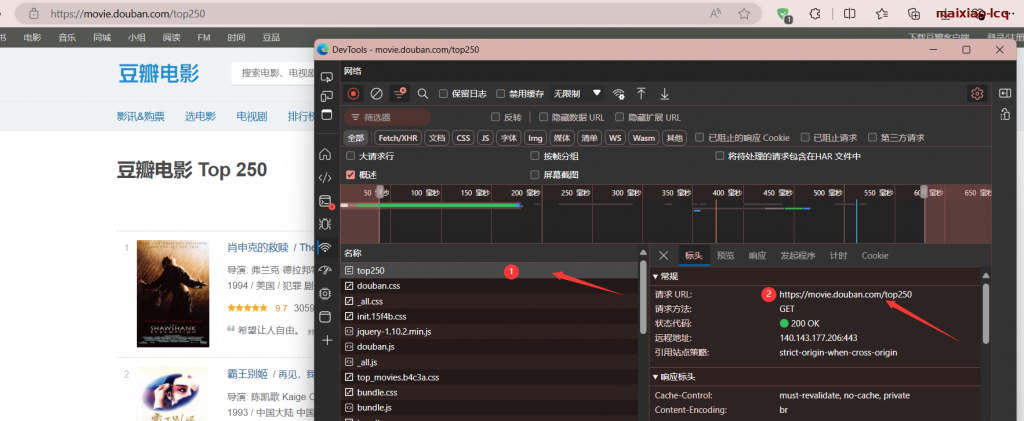
3.1 首先我们要去打开豆瓣top的网页去获取url,打开按下键盘的F12到调试模式找到top250开头的文件,得到url,这是个重要的步骤
3.2我们还需要获取这个页面的UA头,如图
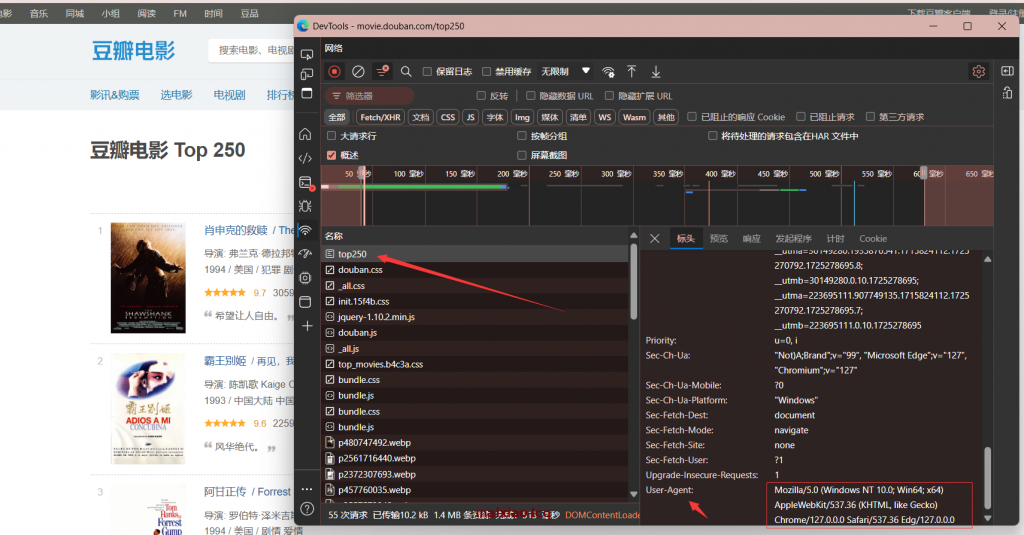
这里我么就可以获取到UA头信息
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
}

3.3然后我们就需要去看一下前端代码,也就是html文件,很简单,也是在调试模式里看,里面有我们需要的内容

3.4我们需要那些数据呢:
我们往下翻可以找到如图数据
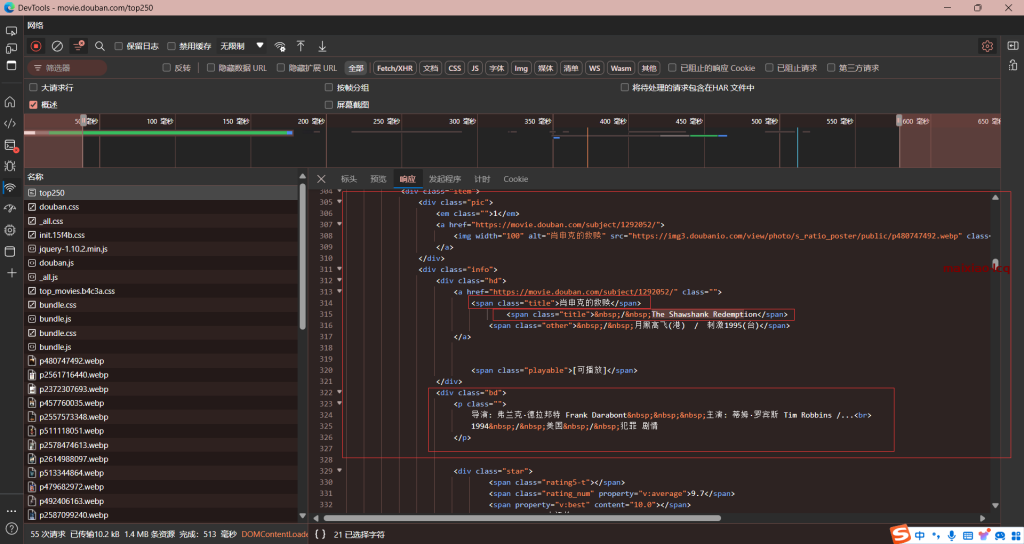
- 电影名字
- 电影英文名字
- 导演
- 主演
- 年份
- 类型
- 属地
- ......
- 根据自己需要爬取的内容来写
我们可以看到这些都是属于在标签和索引中
这里我们需要用到xpath语法
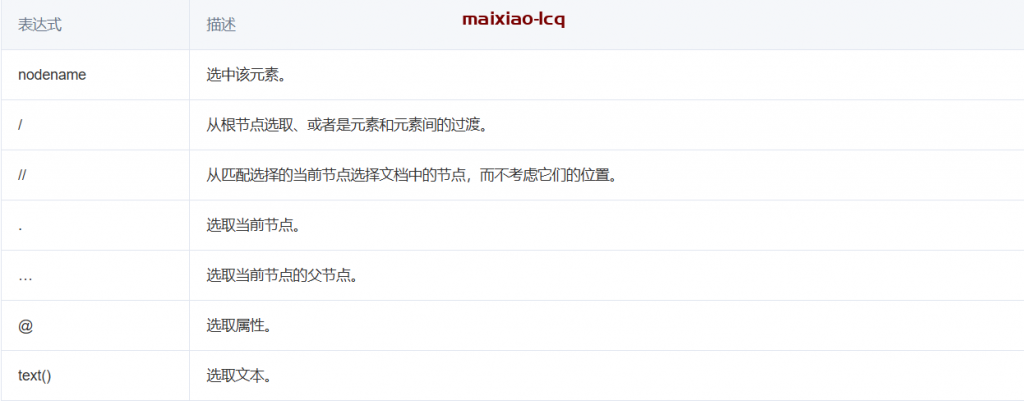
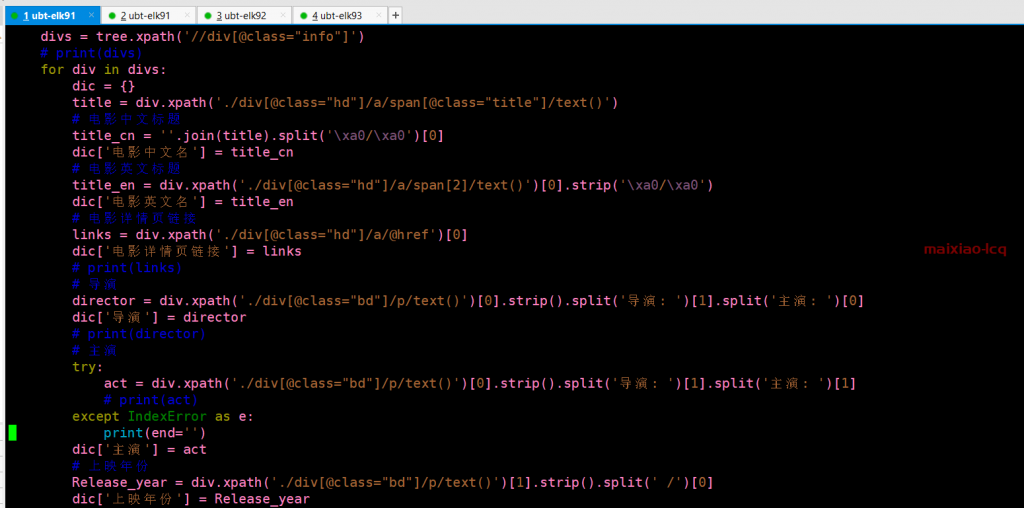
3.5然后就是可以写代码:获取我们所需要的内容
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>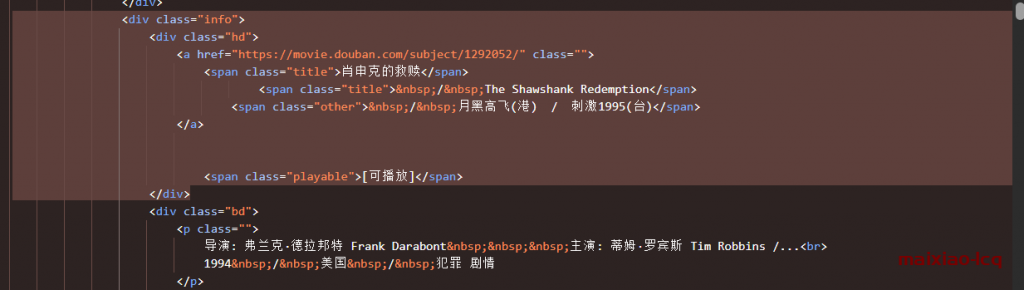
结合图和代码
//div[@class="info"] 这就是我们要得到的节点,所有这个内容的信息都在div class=”info”这个标签下,根据xpath我们就可以获取一个电影的所需要的所有信息
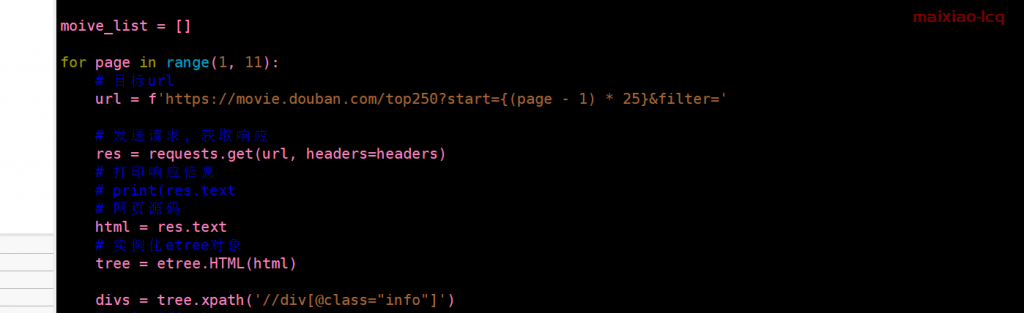
3.6然后发送请求获取该页面的信息
因为一个页面不可能有所有的电影,所以要分页
那么分页可以在url里找到
https://movie.douban.com/top250?start=25&filter=
这里我们可以看到他一共是有25页的,那么接下来的代码也好解释了
3.6最后我们就可以把内容输出
这里我们看到,我们把内容写到了一个叫lcqdouban.csv的文件里
运行:
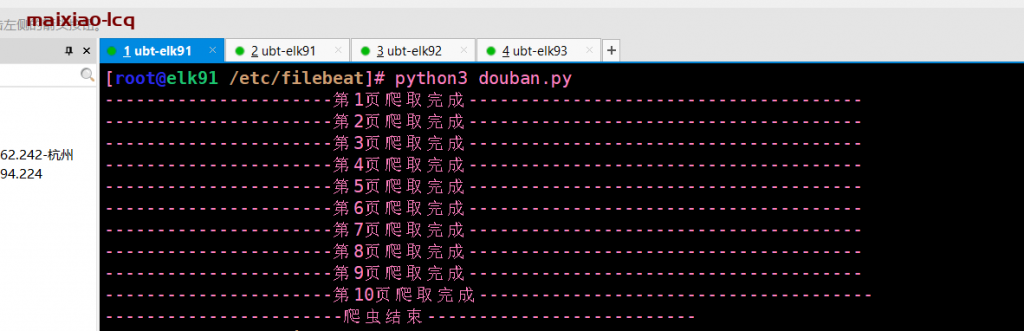
然后再该目录下会生成一个lcqdouban.csv的文件

然后我们导入到windows桌面,看效果

4. 整个代码
[root@elk91 /etc/filebeat]# cat douban.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author : liuchengqi
# 导入模块
import requests
from lxml import etree
import csv
# 请求头信息
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
}
moive_list = []
for page in range(1, 11):
# 目标url
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# 发送请求, 获取响应
res = requests.get(url, headers=headers)
# 打印响应信息
# print(res.text
# 网页源码
html = res.text
# 实例化etree对象
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
for div in divs:
dic = {}
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
title_cn = ''.join(title).split('\xa0/\xa0')[0]
dic['电影中文名'] = title_cn
# 电影英文标题
title_en = div.xpath('./div[@class="hd"]/a/span[2]/text()')[0].strip('\xa0/\xa0')
dic['电影英文名'] = title_en
# 电影详情页链接
links = div.xpath('./div[@class="hd"]/a/@href')[0]
dic['电影详情页链接'] = links
# print(links)
# 导演
director = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[0]
dic['导演'] = director
# print(director)
# 主演
try:
act = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[1]
# print(act)
except IndexError as e:
print(end='')
dic['主演'] = act
# 上映年份
Release_year = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[0]
dic['上映年份'] = Release_year
moive_list.append(dic)
print(f'----------------------第{page}页爬取完成--------------------------------------')
print('-----------------------爬虫结束--------------------------')
# 数据保存
with open('lcqdouban.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 1. 创建对象
writer = csv.DictWriter(f, fieldnames=('电影中文名', '电影英文名', '电影详情页链接', '导演', '主演', '上映年份', '国籍', '类型', '评分', '评分人数'))
# 2. 写入表头
writer.writeheader()
# 3. 写入数据
writer.writerows(moive_list)
[root@elk91 /etc/filebeat]#
Comments 1 条评论
1